Last Updated On: 2020-07-11 16:31
Autoencoders
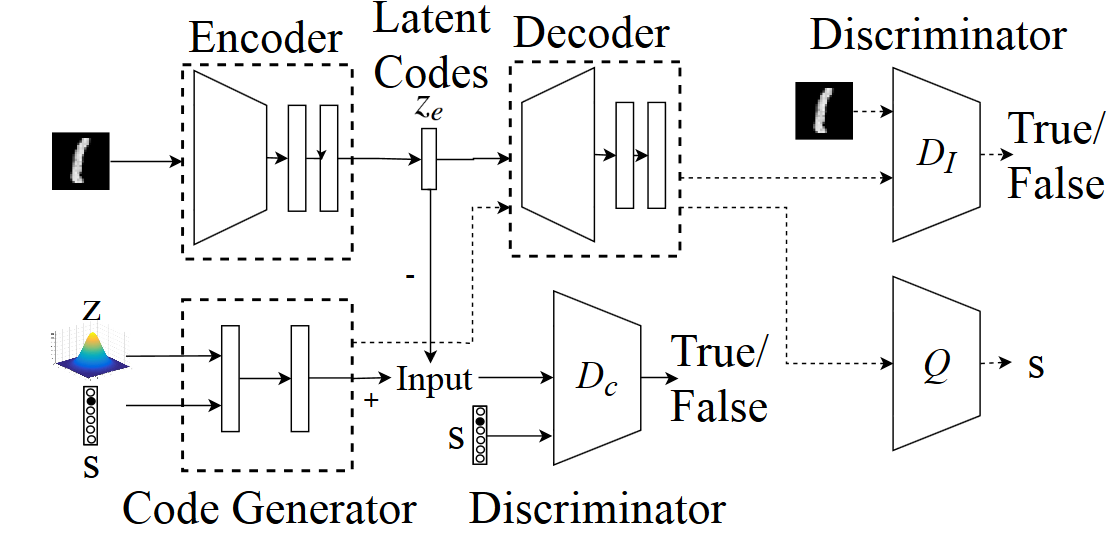
Table of Content
- Autoencoders
- Comments
Introduction
- Type of Autoencoders
- Vanilla Encoder Decoder model and its variants
- Regularized Autoencoders
- Sparse Autoencoders
- Denoising Autoencoders
- Contractive Autoencoders
- Variational Autoencoders
- Conditional Variational Autoencoders
- Adversarial Autoencoders
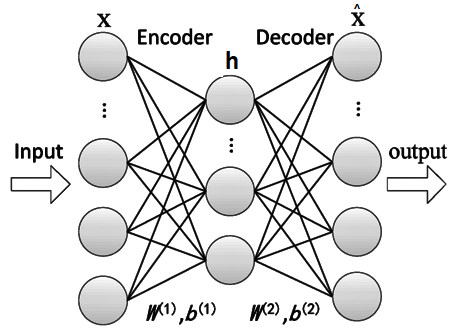
Vanilla Autoencoder model and its variants
-
Simple Encoder Decoder models.
-
Condensed vector representation of Input.
-
Autoencoder without activation function and mean squared error as loss function is same as PCA(Principal Component Analysis).
-
Sometimes the optimal model comes out to be a linear model(PCA), means without activation functions {it can be proved by using singular value decomposition}.
-
Undercomplete and overcomplete Autoencoder
-
Undercomplete : Hidden layer (condensed latent vector) has lower dimension then the input.
-
Overcomplete : Hidden layer has higher dimension then the input.
-
-
One Layer Encoder
-
One Layer Decoder
-
Loss function and its derivative
(1) mean squared error, maximum likelihood, sum squared error, or Squared Euclidean Distance
(2) Bernoulli negative log-likelihood, or Binary Cross-Entropy -
Backpropogation(Weight Updation)
Regularized Autoencoders
- L1 and L2 Regularization
- L1 Regularization :
- L2 Regularization :
Denoising Autoencoder
- DAEs take a partially corrupted input and are trained to recover the original undistorted input
- Stocastic mapping procedure is used to corrupt the data
Sparse Autoencoder
-
Sparse autoencoder may include more (rather than fewer) hidden units than inputs, but only a small number of the hidden units are allowed to be active at once.
-
Loss Function
: sparsity penalty
Contractive Autoencoder
-
Loss Function
: Frobenius Norm
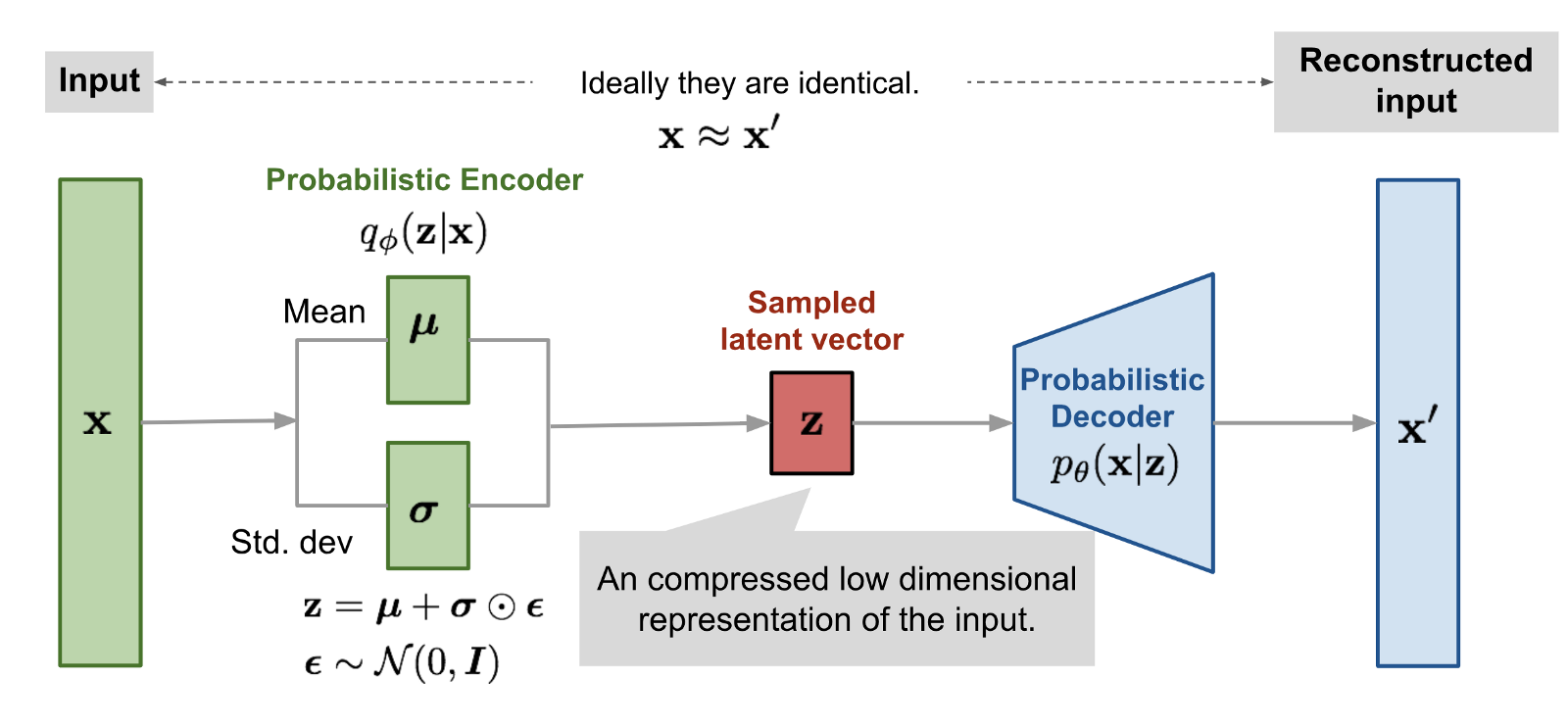
Variational Autoencoder
Mathematics
- Expectation Value
- Monte Carlo Estimation of Expectation
- Bayes Theorem
- Naive Bayes Algorithm and its trainig strategies
- Variational Inference
- KL divergence
Expectation
- Expectation or Expected value of some random variable X with outcomes(finite) as with probabilities as
-
X is a continuous event the change summation to integral.
-
Conditional Expectation
- is called cardinality of Z
Bayes Theorem
-
More elaborate guide is here
-
In probability theory and statistics, Bayes' theorem (alternatively Bayes's theorem, Bayes's law or Bayes's rule) describes the probability of an event, based on prior knowledge of conditions that might be related to the even [wikipedia defination]
-
Bayes theorem gives the measure of the probability of a hypothesis z, given some new data x.
- Its Derivation
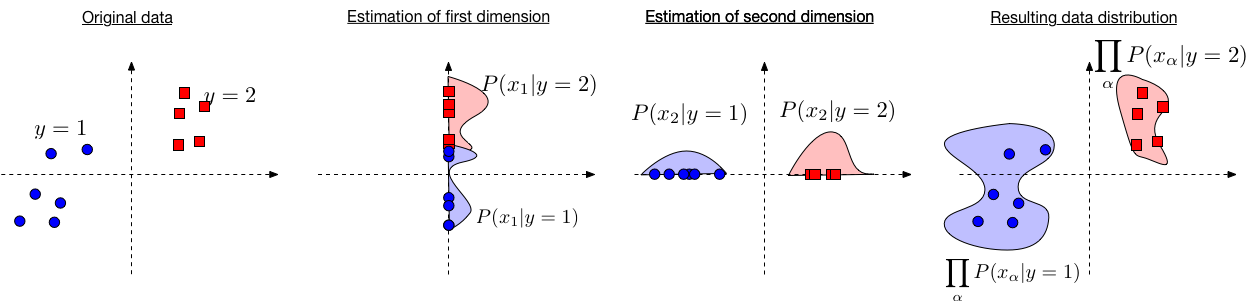
Naive Bayes Algorithm and its training strategies
Ref : http://www.cs.cornell.edu/courses/cs4780/2018sp/lectures/lecturenote05.html
-
Bayesian Classification : Lets assume that labels has to be predicted using a data point , hence the probalitistic output(i.e class score) of the event is,
And, According to the Bayes Theorem.
-
So, if we some how calculate the value of then the problem is solved. Such type of probilistic model is called generative modeling in which we are generating data given its label. In general such training is very difficult.
-
First naive bayes assumption: feature values are independent given the label.
-
Hence, the Problem of simplified to maximizing posterior with above assumption become,
-
But when the Sample points belongs to the any random distribution then the problem becomes intractable. But, If we assumne a definate distribution for the input data like Gaussian distribution then model data point by calculation mean and variation particular to the labels.
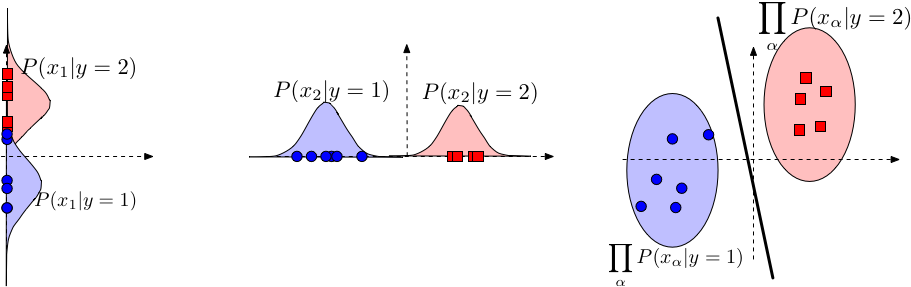
-
Variational Autoencoder has bases lies in Naive bayes Algorithm
Variational Inference
- Problem with the Bayes Theorem: the denominator term in the equation is intractable as computer has to perform integrals for the all values in .
-
So the way around is to rather Approximate it by assuming a function such that,
Where is tractable while is not.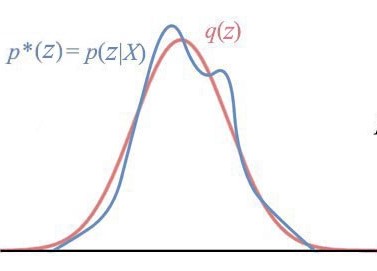
-
Then, find the setting of the parameters that makes the choosen distribution close to the posterior of interest.
-
One method to achieve the variational inference is KL divergence
Kullback-Leibler (KL) Divergence
-
KL divergence measures the closeness of two distributions.
Higher the probablity of an event, lower will be its information content. i.e information is inversly proportional to the probability of the event.
For example : Lower temperature at any day on june(summer) is less likely but it has high information content about the weather conditions of that day. -
Information Content of an event w.r.t some probabilty distribution .
-
KL divergence is the Expectation value of the change in information content
-
Kullback-Leibler (KL) is not symmetric.
-
Evidence Lower Bound (ELBO) :
- We actually can’t minimize the KL divergence exactly, but we can minimize a function that is equal to it up to a constant.
What VAE Offers
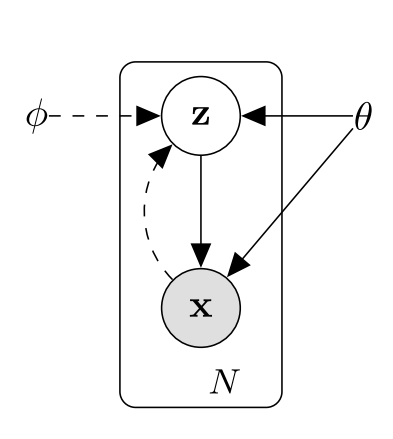
-
As naive bayes says that computation of is a generative modelling problems so, starting from that,
-
Assume as generative model, but for the computation of the equation there is a requirement of posterior which is forms the equation.
-
Due to which is intractable whole equation 1 become intractable.
-
So using variational inference, assume a variational Approximation (Which works as a recognition model) for the .
-
Now there are method to find the parameters for called Variational Bayesian methods, like mean-field Variational inference, Factorized approximation, KL divergence.
-
But in VAE parameters for are learned jointly with the generative model parameters .
VAE Loss function Derivation
NOW :
Proof : //TODO
- On combining above two equations
- The right hand side of the equation is the Evidence Lower Bound (ELBO) :
- Therefore maximizing the ELBO maximizes the log probability of our data by proxy. This is the core idea of variational inference
- Kullback-Leibler term in the ELBO is a regularizer because it is a constraint on the form of the approximate posterior.
- second term is called a reconstruction term because it is a measure of the likelihood of the reconstructed data output at the decoder.
- Negation of the ELBO is the loss function for VAE
Derivative of loss function
-
For wait upgradation there is need of which is taking as constant and taking as constant
-
Derivation w.r.t is OK but w.r.t is problematic because of the as the Expectation depends on the variable
-
Using Monte Carlo estimation
-
Reparameterization Trick
-
This strategy is used to make monte carlo estimate of Expectation differentiable by rewriting the Expectation with respect to
Matrix Maths and Training
Conditional Variational Autoencoders
Adversarial Autoencoders
Tensorflow Implementation
Full Implementation of different Autoencoder is Available on my kaggle account link is here
References
- Chapter 14: Autoencoders {Deep Learning; Ian Goodfellow}.